You Can’t Be Fair to Everyone
Algorithmic fairness has inherent mathematical limits

As Machine Learning (ML) is increasingly used across core social domains such as advertising, credit, employment, education, and criminal justice to assist (when not making decisions altogether) decision-makers, it is crucial to ensure that these decisions are not biased or discriminatory. In some jurisdictions, those domains are protected by anti-discrimination laws, making measuring and ensuring fairness a legal issue more than just an ethical one. For example, a White House report released in 2016 called for “equal opportunity by design” as a guiding principle in domains such as credit scoring.
Threshold classifiers: a loan granting use case
Some ML systems that are subject to the risk of discrimination are those powered by threshold classifiers. A threshold classifier is an algorithm that takes a yes/no decision, putting things in one category or another. The case study below is from a paper published by Hardt et al. (Google Research) and explained in layman terms on the Google Research website. It is a straightforward loan granting scenario, where a bank may grant or deny a loan based on a credit score calculated by an ML algorithm. The bank chooses a particular threshold, and people whose credit scores are below it are denied the loan, while people above it are granted the loan.
What turns an apparently pure business decision like granting/rejecting a loan into a potentially discriminatory one is the inevitable presence of protected attributes such as race, religion, gender, disability, or family status in the datasets.
A naïve approach might require the algorithm to ignore all protected attributes. However, this idea of “fairness through unawareness” is ineffective due to the presence of redundant encodings, attributes that work like proxies for protected attributes. Bias finds his way from the rest of the data through proxies: for example, in attributes like postcode or address, or the school that was attended, and many more.
In law, bias means a judgment based on preconceived notions or prejudices as opposed to an impartial evaluation of facts. In computer science, though, fairness, or the absence of bias, must be defined in mathematical terms.
For example, in the loan granting problem, we could propose that the same proportion of white and black applicants should be granted loans (statistical parity) or that all individuals who qualify for a desirable outcome should have an equal chance of being correctly classified (equal opportunity). Another one could be that the ratio in the probability of favourable outcomes between the two groups be the same (disparate impact), or try to equalize the error rates across groups so that the algorithm makes just as many mistakes on white applicants as it does on black applicants (treatment equality). So we must choose a metric to optimize among many possible ones that are mutually exclusive. If you optimize for statistical parity, you cannot optimize for equal opportunity at the same time, and so for the others, because, as it has been shown in many publications, there are tradeoffs that pose a mathematical limit to how fair any algorithm, or human decision-maker can be.
In the diagram below, dark dots represent people who would pay off a loan, and light dots those who wouldn’t. In an ideal world, we would work with statistics that cleanly separate categories, as in scenario A. Unfortunately, it is far more common to see scenario B, where the groups overlap.

Choosing a threshold requires some tradeoffs. Too low, and the bank would give loans to many potential defaulters. Too high, and many people who would usually qualify for a loan won’t get one. So what is the best threshold? It depends on what we want to optimize. We might want to minimize wrong decisions, as they are costly for the bank. Another one could be to maximize profit. Assuming a successful loan makes the bank $300, but a default costs $700, we can then calculate a hypothetical “total profit” (or loss) as a result of the threshold we choose.

Bias mitigation strategies
What happens if we have two subgroups, defined by a protected attribute like race or sex, where a statistic like a credit score is distributed differently between two groups? We will call these two groups “blue” and “orange.”
If we choose the pair of thresholds that maximize total profit for the bank, we can see in the diagram below that the threshold assigned to the blue group is higher than the one chosen for the orange group resulting in only 60% of their qualifying applicants to be granted a loan (true positive rate) vs 78% of the orange group.
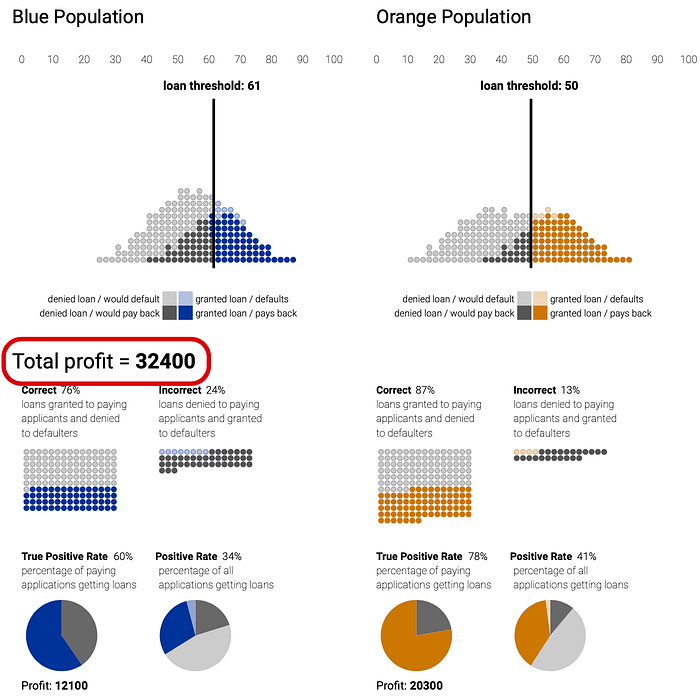
One obvious solution would be for the bank to implement a group-unaware strategy by selecting the same threshold for both groups. Now the orange group has been given fewer loans. Among people who would pay back a loan, they are at a disadvantage, as the true positive rate is 60% vs 81% for the blue group.
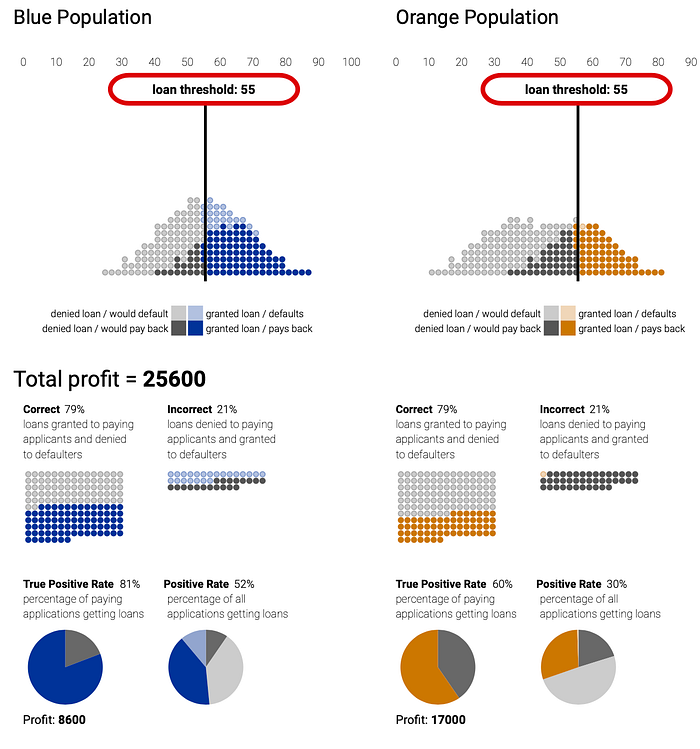
What if we change to another strategy that guarantees the two groups will receive the same number of loans using loan thresholds that yield the same fraction of loans to each group (demographic parity). Again, demographic parity constraint only looks at loans given, not rates at which loans are paid back. In this case, the criterion results in fewer qualified people in the blue group being given loans than in the orange group.
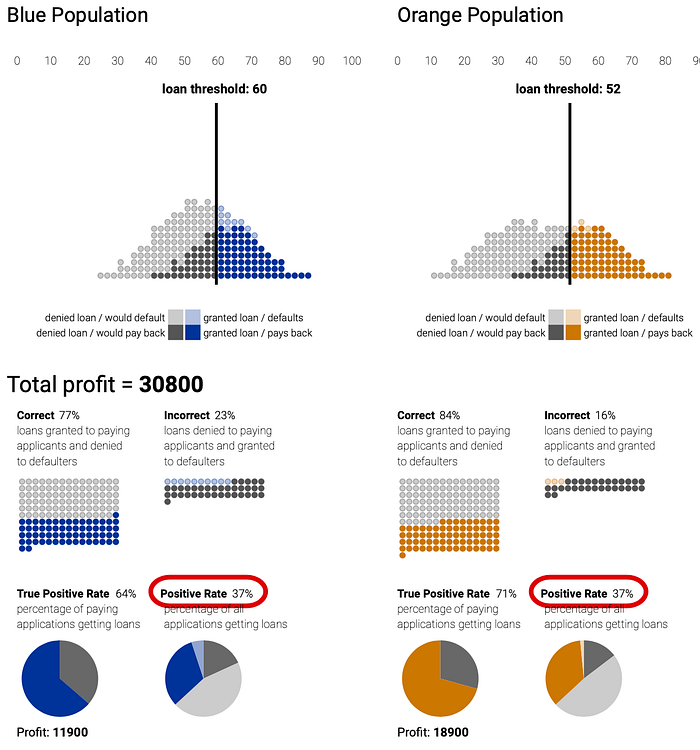
One final attempt can be made by adopting a metric called equal opportunity, which enforces the constraint that among the people who can pay back a loan, the same fraction in each group should actually be granted a loan. Now the true positive rate is identical between the two groups. The interesting part is that this choice is almost as profitable for the bank as demographic parity, and about as many people get loans overall.
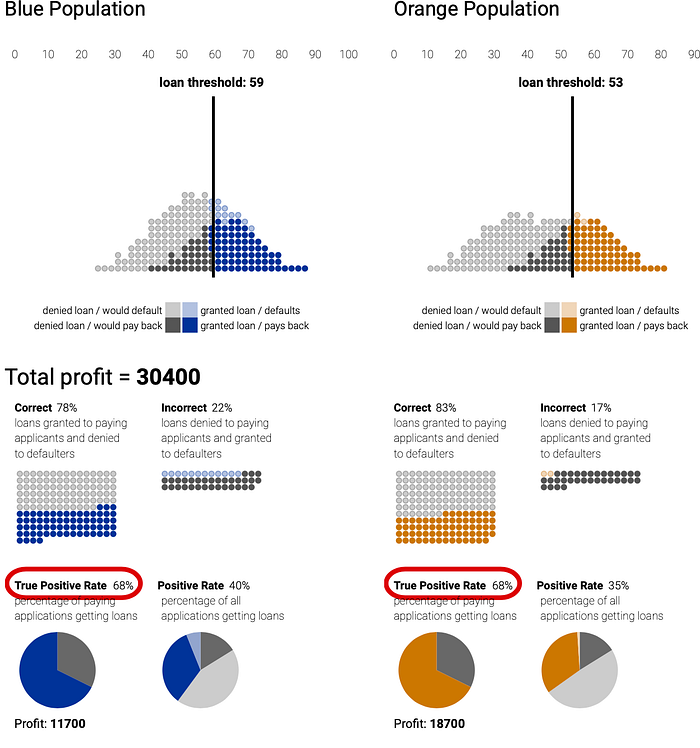
The paper published by Google research shows that given essentially any scoring system — it is possible to find thresholds that meet any of these criteria. In other words, even if you don’t have control over the underlying scoring system (a typical case), it’s still possible to attack the issue of discrimination. However, it shows that it is mathematically impossible to find a combination of thresholds that simultaneously satisfy all the fairness criteria: you need to pick one.
Conclusions
ML algorithms are very good at optimizing a single metric. But things get complicated if we want to measure the fairness of an algorithm in the presence of protected attributes. Fairness needs to be mathematically formulated in a way that can be utilized in ML systems, that is, quantitatively: here you will find more than 20 definitions of fairness, yet there is no clear agreement on which definition to apply in each situation. Moreover, those are usually mutually exclusive, as algorithms cannot optimize for more than one metric at a time. The use case above shows that bias can be mitigated by choosing among different fairness metrics to optimize with little impact on the business metrics, but there will always be tradeoffs because of the mathematical limits of how fair any algorithm, or human decision-maker can be.